
近两年,大数据分布式架构成为金融行业关键词汇,围绕分布式架构分布式计算、分布式存储、分布式网络成为信息科技的主流。金融各个子行业包括银行、保险、证券、信托行业,纷纷采取分布式架构和相关技术建设新系统或重构原有系统,利用分布式架构的高可扩展性、高处理效率、强容错能力特点,来提升信息系统的灵活性,降低成本,保障供应安全。

中金智汇的大数据架构经历了三个主要阶段:
a. 使用Gearman基于MapReduce思想实现自研的分布式处理架构。
b. 引入Hadoop解决自研分布式处理架构网络IO问题。
c. 引入Spark解决Hadoop小规模数据集处理性能不足,以及磁盘IO等问题。
1.1 Gearman
架构

Gearman驱动的应用程序由三部分组成:Client(客户端),Worker(工作者)和JobServer(作业服务器)。
· Client负责创建要运行的作业并将其发送到JobServer。
· JobServer将找到一个合适的工作人员,可以运行该作业并转发给Worker。
· Worker执行Client的工作,并通过JobServer向Client发送响应。
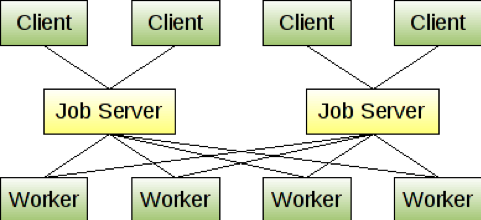
Gearman提供应用程序调用的Client和Worker API,以与Gearman JobServer(也称为gearmand)进行通信,因此无需处理网络或作业映射。在内部,Gearman Client和Worker API使用TCP协议与JobServer通信。
优点
Gearman实现了基本的MapReduce思想,Client将一个大任务拆分成多个小任务后,发送给多个Worker并行处理,将处理结果返回Client。
缺点
Gearman在处理大量数据的场景下,由于JobServer不清楚要处理的数据存储到哪个对应的Worker上,所以导致Worker接到任务时首先需要去公共存储中获取数据,导致大量的网络IO,从而导致性能不足。
1.2 Hadoop
架构
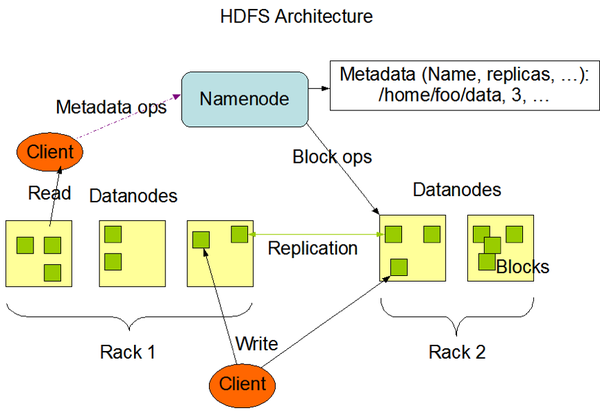
HDFS集群由NameNode管理文件系统命名空间的主服务器和管理客户端对文件的访问组成。此外,还有许多DataNode,通常是群集中每个节点一个,用于管理连接到它们运行的节点的存储。HDFS公开文件系统命名空间,并允许用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组DataNode中。
· NameNode执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。它还确定了块到DataNode的映射。
· DataNode负责提供来自文件系统客户端的读写请求。 DataNode还根据NameNode的指令执行块创建,删除和复制。
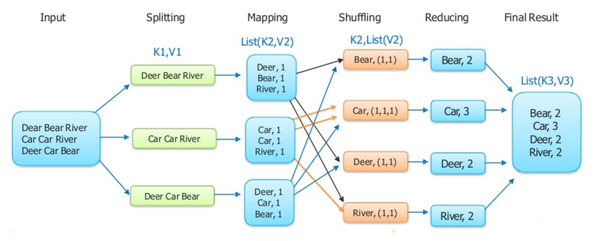
Hadoop MapReduce作业通常将输入数据集拆分为独立的块,这些块由Map任务以完全并行的方式处理。Hadoop MapReduce对Map的输出进行排序,然后输入到Reduce任务。通常,作业的输入和输出都存储在文件系统中。Hadoop MapReduce负责调度任务,监视它们并重新执行失败的任务。
优点
Hadoop已经完全实现了MapReduce的分布式处理思想,同时在其基础上完成失败重试等功能。同时在Hadoop的架构设计中,由于NameNode已经记录了每个数据块具体存在哪些个DataNode上,所以在执行Map任务的分发时,会根据NameNode的存储记录表,将需要处理的任务直接分发到有该任务需要的数据的DataNode上进行处理,解决了之前介绍Gearman的缺点,从而导致DataNode处理任务时,不需要去其他服务器获取数据,解决了网络IO瓶颈的问题,提高了任务处理效率。
缺点
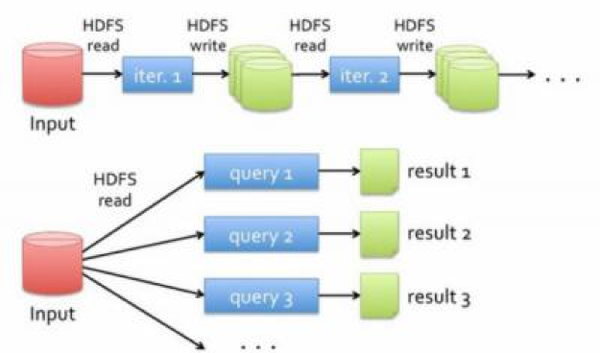
由于Hadoop设计时算子单一(只有Map和Reduce)导致如果要完成一个多步骤任务时,每一个步骤都需要写一个Map和Reduce,同时每个Map和Reduce的执行过程代表数据至少会落地一次,所以导致执行整个任务中会出现大量的磁盘IO,从而影响了处理效率。
1.3 Spark
架构
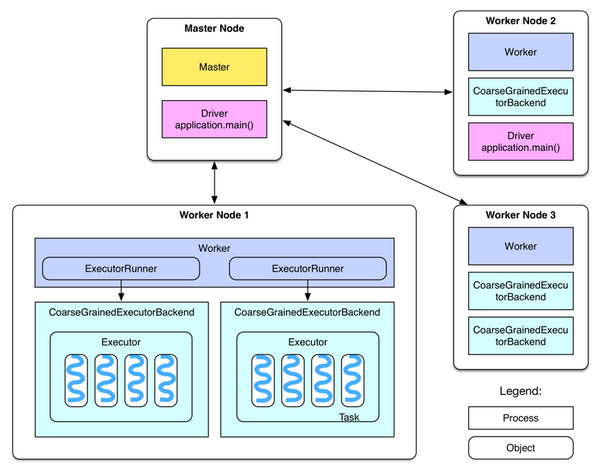
· Spark中的Driver即运行程序的主函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver。
· Executor是某个Application运行在工作节点上的一个进程, 该进程负责运行计算任务,并且负责将数据存到内存或磁盘上,每个程序都有各自独立的一批Executor,在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将任务包装成TaskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个CoarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的Cpu个数。
优点
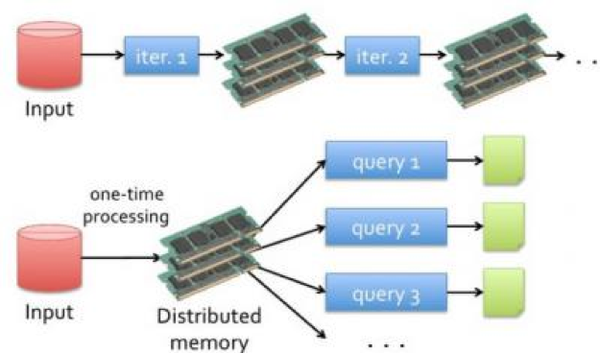
和Hadoop MapReduce相比Spark通过使用内容代替磁盘作为处理过程中间数据的存储,从而减少了在磁盘IO上的开销,解决了Hadoop的性能问题。同时设计了弹性分布式数据集(RDD)的数据结构作为数据处理的基础单元,配合有向无环图(DAG)、Pipline等技术减少了运算步骤,提高了执行效率。
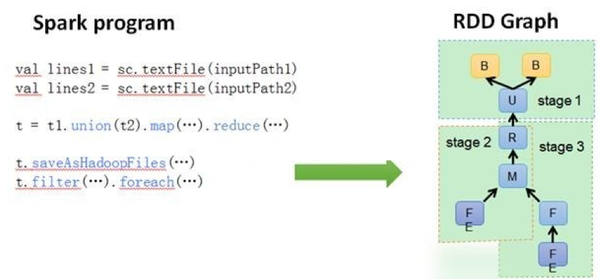
1.4Hadoop+Spark
原理

由于Spark最出色的就是计算框架,其资源调度框架(Standalone模式)对复杂场景的资源调度略显不足。所以和Hadoop的资源调度框架(Yarn)和底层存储框架(HDSF)组合使用,这样做既可以继承了Spark计算框架的全部优势,也可以解决了Hadoop MapReduce的问题。


广发银行信用卡中心,拥有6000余坐席,约4.2亿 通电话/年,每天3.6万小时 的语音量,最初领导层根据企业发展战略,预见了未来企业自身和应用技术的发展趋势,早在2014年便与原中金数据大数据事业部现中金智汇签订了合作协议,运用分布式大数据底层架构开展上层业务。
中金智汇利用分布式大数据技术架构,将原来无法方便处理、 非结构化的数据进行解析、分析和挖掘 。将原来每天必须要人工抽样的低效模式,变成每天使用机器全量的高效模式。使得卡中心从原来一天处理37件,到现在一天可以处理18000件,创造了500%的颠覆性提升 。
中金智汇通过四年来语音库数据的积累,结合分布式大数据技术架构、产品快速创新能力和深入行业的应用经验。不断的对积累数据进行分析和挖掘,去寻求和发现海量数据背后的价值,从而衍生了多种适合卡中心的分析和挖掘的数据模型。使得卡中心在客户投诉率下降10%-20%,客户满意度上升10%-20%,员工技能提升5%-15%等等的业务价值增长。为其改善了风险防控之外的服务流程优化 20 余项,陆续开拓了营销效果监控及信审合规等业务范围,为广发银行在智能营销、信用卡分期方面带来极大营收。
凭借技术的先进性、产品的创新性、方案的有效性,中金智汇积累了金融、政府、互联网等多个行业大中型客户的成功应用案例,并得到了市场的广泛认同,陆续服务包括交通银行、大地保险、同程旅游、中国一汽等在内的数十家大中型企业客户,积累了跨银行、保险、商旅、车企、物流、BPO等多个行业与领域的客户案例,并与中科院声学所、北京邮电大学、腾讯、第四范式等资深科研机构及领军行业企业建立了广泛的合作关系。

大数据的未来就是人工智能,而人工智能需要依靠底层分布式大数据架构的支撑得以实现。中金智汇利用底层分布式大数据架构结合语音识别、NLP/NLU、深度学习等技术在联络中心数据分析、实时坐席助手 等场景均实现了可用于生产的智能应用产品。当然,这还远远不够……
“这是一个最好的时代”!在未来,中金智汇会基于大数据架构体系及完备的应用场景结合产品快速创新能力,为追求高效客户经营能力的企业,提供领先、专业、可靠的智能化应用产品和服务,而持续努力着!
 扫码关注视频号
扫码关注视频号
 扫码关注公众号
扫码关注公众号
中金智汇科技有限责任公司 Copyright 2018 All Rights Reserved 京ICP备18001296号 ![]() 京公网安备 11030102010370号 网站建设
京公网安备 11030102010370号 网站建设

